GIS Research UK 2022
Up-scaling a Spatial Survey with Propensity Score Matching:
Implications of a Motorbike Ban in Hanoi
Nick Malleson, et al.
Professor of Spatial Science
School of Geography, University of Leeds, UK
www.nickmalleson.co.uk
These slides: www.nickmalleson.co.uk/presentations.html
This work has received funding from the British Academy under the Urban Infrastructures of Well-Being programme [grant number UWB190190].
Co-authors
Lex Comber, Kristina Bratkova, Phe Hoang Huu, Minh Kieu, Thanh Bui Quang, Hang Nguyen Thi Thuy, and Eric Wanjau
University of Leeds; University of Auckland; Vietnam National University; R&D Consultants

Context
Transport in Há Nội
City (8M people) growing faster than transport infrastructure
Causing issues of congestion and pollution
`Non-western' transport behaviours, e.g. 90% motorbikes
Implications for Urban Data Science and traditional transport models
Urban Transport Modelling for Sustainable Well-Being in Hanoi (UTM-Hanoi)
2+ year project funded by the British Academy
Aim: new data collection and analysis/modelling to inform transport policy
Project website: https://urban-analytics.github.io/UTM-Hanoi


Up-scaling a Spatial Survey

Data
Bespoke travel survey
30,000 responses
Ask about demographics, travel behaviour (main journeys), (aspirational) vehicle ownership, potential motorbike ban.
Vietnam Census (sample of micro-data)
Aims
Upscale the survey to make it more representative (larger sample and less bias)
Use propensity score matching
Better understand the possible implications of a motorbike ban
Propensity Score
Common in medicine
Converts observational studies (with non-random sampling) to experimental studies
Tries to balance two groups — 'control' and 'treatment' — so that they have similar characteristics.
Allows differences to be attributed to the effect of the treatment, rather than to differences in the two groups
Propensity Score Matching (PSM)
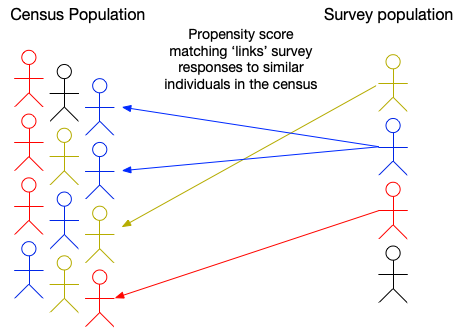
Following Morrissey et al (2015) and Spooner (2021)
1: Assign treatment (census) and control (survey) groups
2: Calculate the propensity score
"probability of treatment assignment conditional on observed baseline characteristics" (Austin 2011)
"most often estimated using a logistic regression model, in which treatment status is regressed on observebaseline characteristics" (Austin 2011)
Here we use a logistic classifier in scikit-learn (Luvsandorj, Z., 2021).
Propensity Score Matching (PSM)
3: Nearest-neighbour algorithm selects individuals in the survey who are close to those in the census
Using scikit-learn NearestNeighbors class.
Current linking attributes: sex, age (6 groups), house ownership (owned, rented, other)
Future work: additional variables, and geography
Propensity Score Matching (PSM)
How well did it work?
Comparing the propensity scores of the treatment (census) and control (survey) groups.
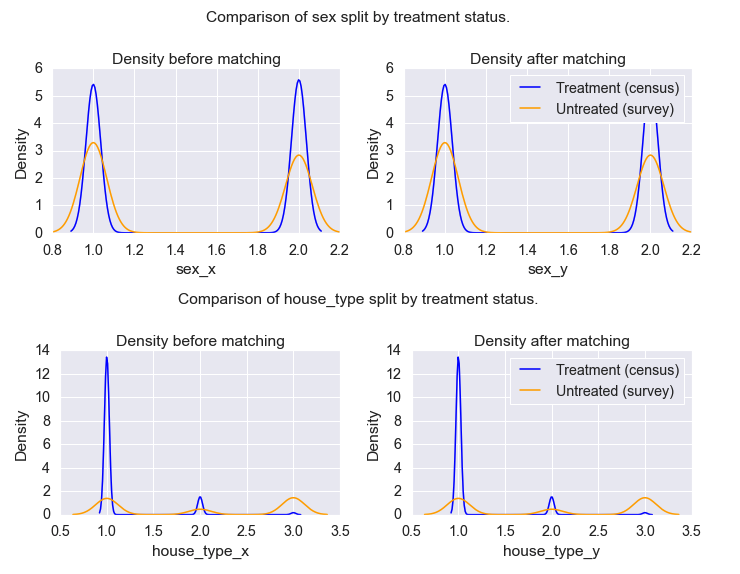
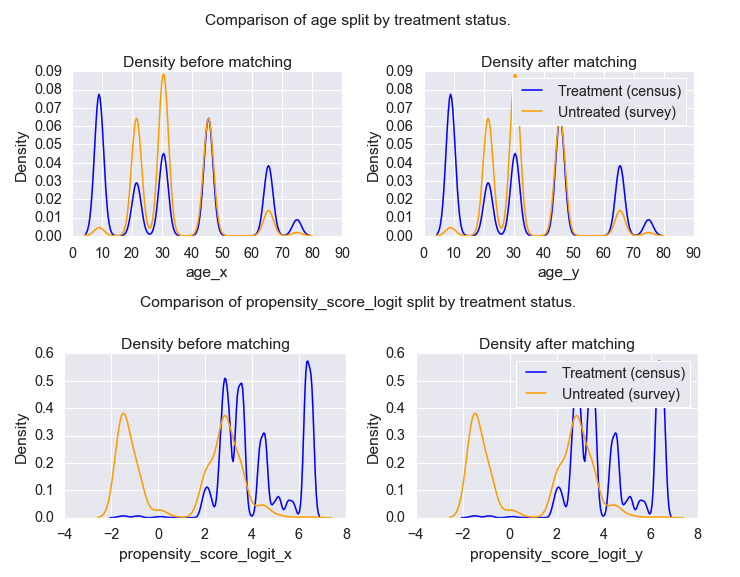
Preliminary Results
Awareness of a possible motorbike ban
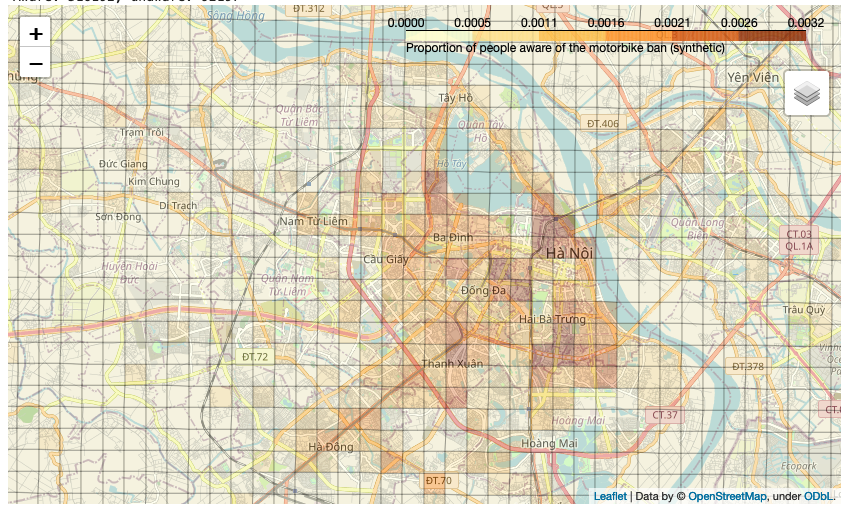
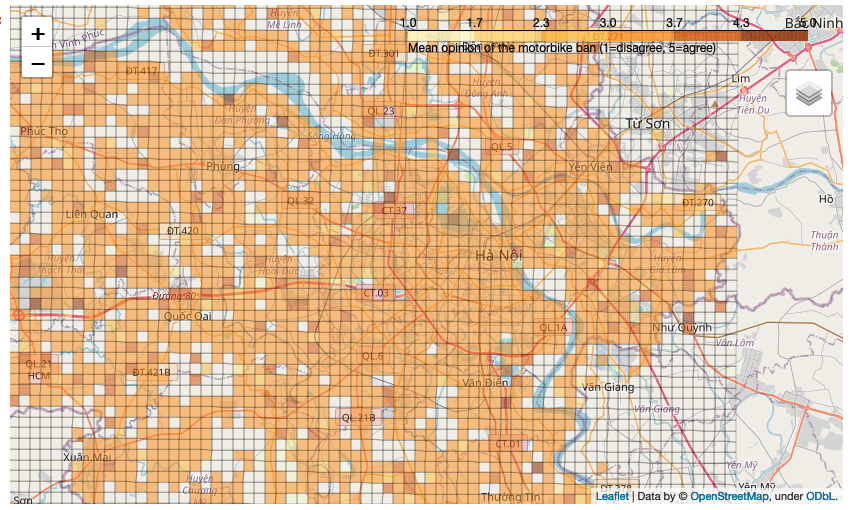
Preliminary Results
Opinion on the possible ban
Summary / Conclusions
Better understand residents' transport opinions and behaviours
Use propensity score matching to up-scale a travel survey
Explore awareness and opinion on a motorbike ban
CAVEAT: Currently too few factors considered, links between the census and the survey are not sufficiently nuanced
Next steps:
Improve census-survey link to be more detailed
Take spatial location into account
Other features of the survey to explore: e.g. aspirational vehicle ownership, journeys, public transport, etc.