CUPUM 2025, UCL, London
Enhancing Spatial Reasoning and Behaviour in Urban ABMs with Large-Language Models and Geospatial Foundation Models
Nick Malleson, Andrew Crooks, Alison Heppenstall and Ed Manley
University of Leeds, UK; University at Buffalo, US; University of Glasgow, UK
n.s.malleson@leeds.ac.uk
Slides available at:
www.nickmalleson.co.uk/presentations.html
Context
Modelling human behaviour in ABMs is (still!) an ongoing challenge
Behaviour typically implemented with bespoke rules, but even more advanced mathematical approaches are limited
Can new AI approaches offer a solution?
Large Language Models can respond to prompts in 'believable', 'human-like' ways
Geospatial Foundation Models capture nuanced, complex associations between spatial objects
Multi-modal Foundation Models operate with diverse data (text, video, audio, etc.)
This talk: discuss the opportunities offered by LLMs, GSMs and MFMs as a means of creating more realistic spatial agents.
But first, where might this lead...
"All models are great, until you need them"
It's fine to use models under normal conditions. Very useful.
Especially if the system undergoes a fundamental change (COVID? Global financial crash?) -- then we really need models to help
But then they're totally useless!
Example: a burglary ABM
Worked great, until COVID...
Maybe a model with LLM-backed agents would be better able to respond after a catastrophic system change
Large Language Models (LLMs)
Early evidence suggests that large-language models (LLMs) can be used to represent a wide range of human behaviours
Already a flurry of activity in LLM-backed ABMs
E.g. AutoGPT, BabyAGI, Generative Agents, MetaGP ... and others ...
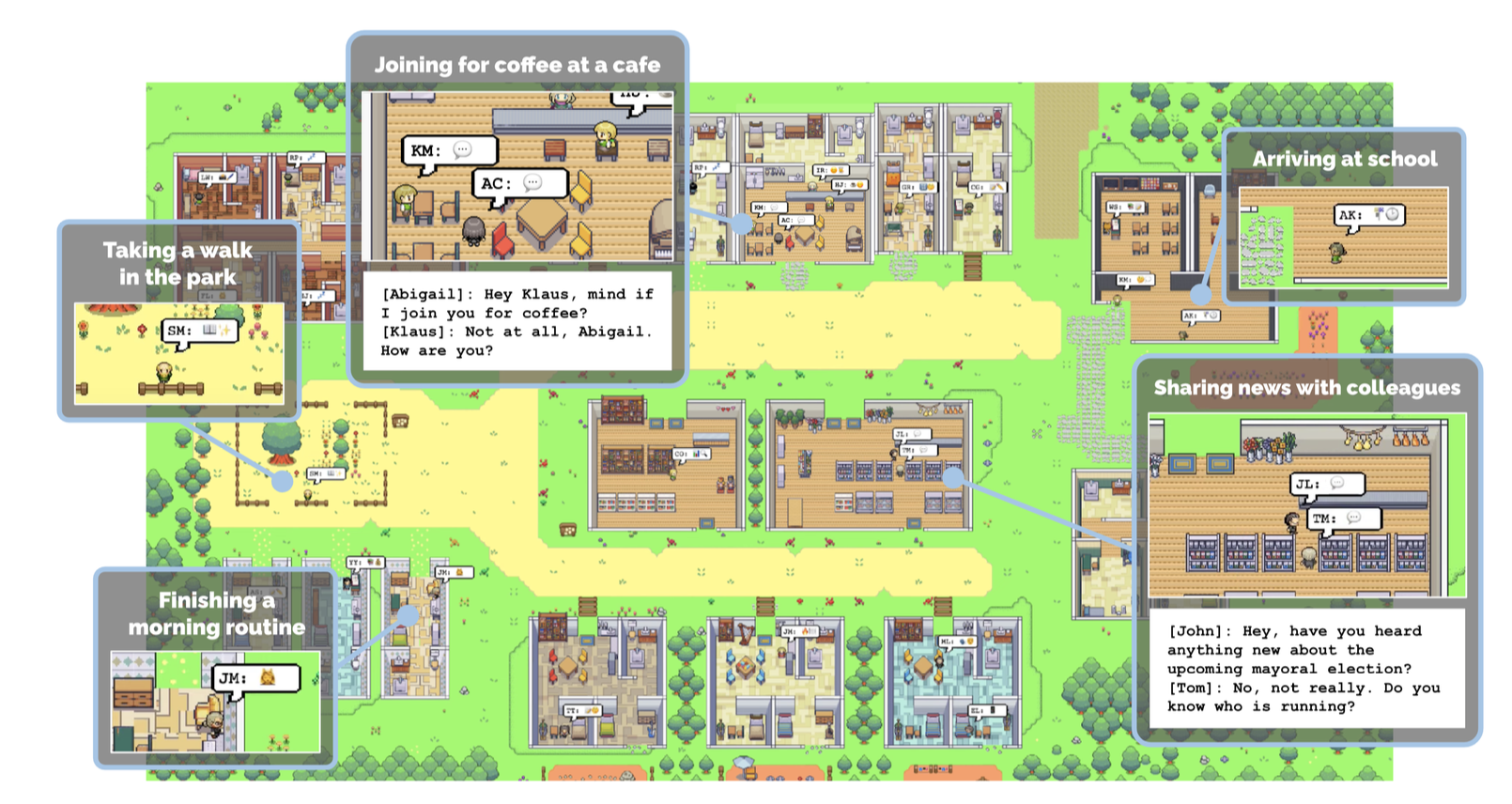
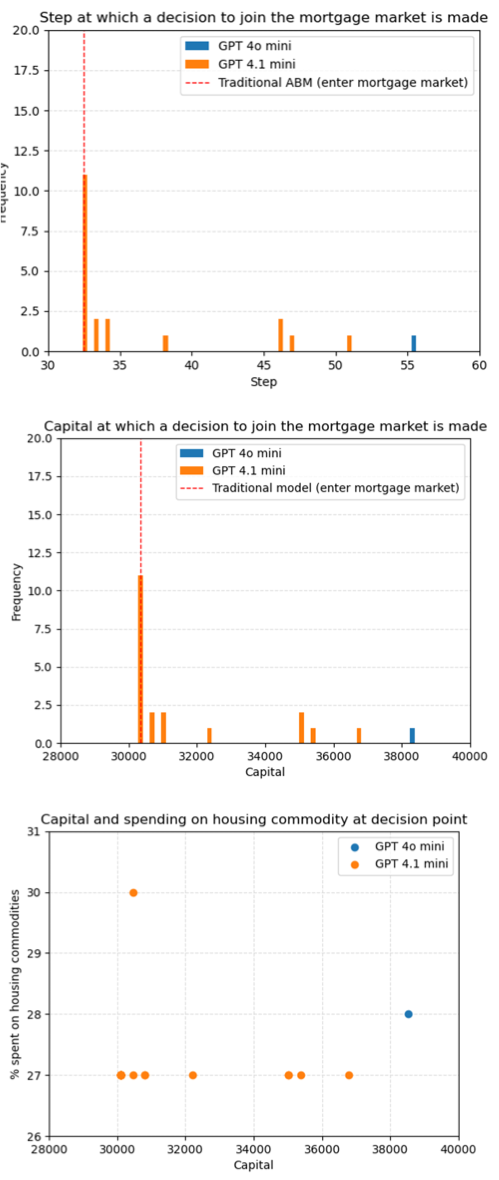
Example: Housing ABM with LLM agents
Can we switch agent behaviour (when to buy, sell or rent houses) from rule-based empirically-driven method to being driven by LLMs?
Traditional agents: Decisions rules are clearly defined
LLM agents: Decision rules are unknown (prompt based on demographics etc.)
Decision points aligned with real observations. Possible insight into latent variables.
LLMs & ABMs: Challenges
Lots of them!
Computational complexity: thousands/millions of LLMs?
Bias: LLMs very unlikely to be representative (non-English speakers, cultural bias, digital divide, etc.)
Validation: consistency (i.e. stochasticity), robustness (i.e. sensitivity to prompts), hallucinations, train/test contamination, and others
Main one for this talk: the need to interface through text
Communicating -- and maybe reasoning -- with language makes sense
But having to describe the world with text is a huge simplification / abstraction
A solution? Multi-modal and Geospatial Foundation Models
Foundation models: "a machine learning or deep learning model trained on vast datasets so that it can be applied across a wide range of use cases" (Wikipedia)
LLMs are Foundation models that work with text
Geospatial Foundation Models
FMs that work with spatial data (street view images, geotagged social media data, video, GPS trajectories, points-of-interest, etc.) to create rich, multidimensional spatial representations
Multi-modal Foundation Models
FMs that work with diverse data, e.g. text, audio, image, video, etc.
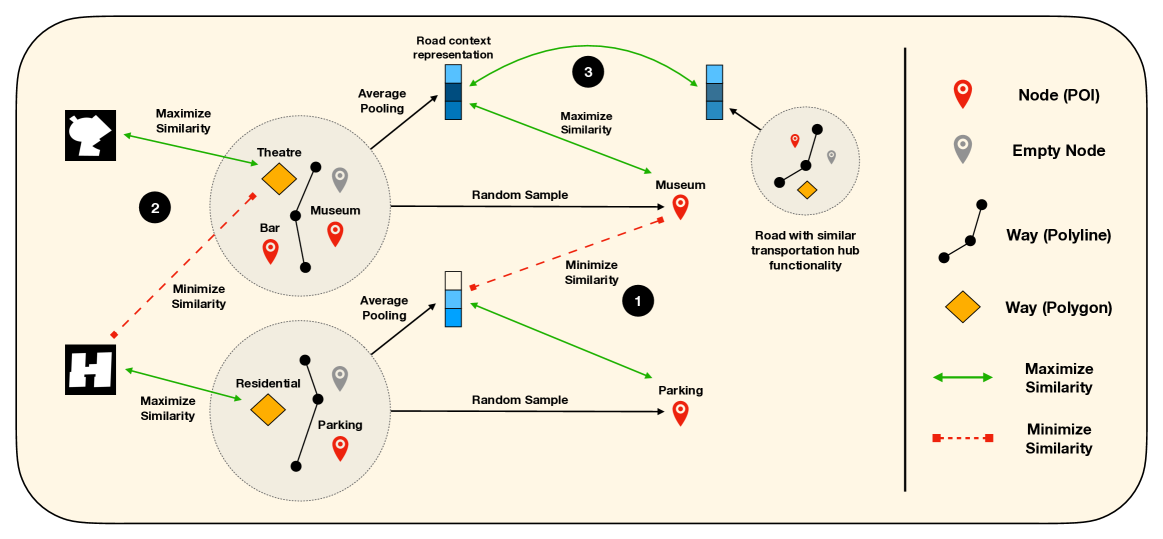
Geospatial Foundation Model Example
Example of a foundation model constructed using OSM data
Embeddings are remarkably good at predicting things like traffic speed and building functionality (zero-shot)
Towards Multi-Modal Foundation Models for ABMs (??)
GFMs and LLMs: a new generation of ABMs?
LLMs 'understand' human behaviour and can reason realistically
GFMs provide nuanced representation of 'space'
How?
I've no idea! Watch this space.
Insert spatial embeddings directly into the LLM?
Use an approach like BLIP-2 that trains a small transformer as an interface between an LLM and a vision-language model
Suggestions welcome!

Summary and Outlook
Huge potential to use LLMs to drive agents in an ABM
But need to overcome some big challenges first
Lots of activity, but very little peer-reviewed
Geospatial (or multi-modal) foundation models could offer a better interface to the environment than text
Maybe...
CUPUM 2025, UCL, London
Enhancing Spatial Reasoning and Behaviour in Urban ABMs with Large-Language Models and Geospatial Foundation Models
Nick Malleson, Andrew Crooks, Alison Heppenstall and Ed Manley
University of Leeds, UK; University at Buffalo, US; University of Glasgow, UK
n.s.malleson@leeds.ac.uk
Slides available at:
www.nickmalleson.co.uk/presentations.html